pi05
这篇文章提出了π0.5模型,通过异构数据协同训练与分层推理架构,解决了机器人在全新家庭环境中执行长视野任务的泛化难题。
Note
website: https://pi.website/blog/pi05
Meta Data
Title: π0.5: a vision-language-action model with open-world generalization
Author: Kevin Black; Noah Brown; James Darpinian; Karan Dhabalia; Danny Driess; et al.
ArXiv id: arXiv:2504.16054
Local Link: Black 等 - π0.5 a Vision-Language-Action Model with Open-World Generalization.pdf
Abstract:\ In order for robots to be useful, they must perform practically relevant tasks in the real world, outside of the lab. While vision-language-action (VLA) models have demonstrated impressive results for end-to-end robot control, it remains an open question how far such models can generalize in the wild. We describe , a new model based on that uses co-training on heterogeneous tasks to enable broad generalization. \ uses data from multiple robots, high-level semantic prediction, web data, and other sources to enable broadly generalizable real-world robotic manipulation. Our system uses a combination of co-training and hybrid multi-modal examples that combine image observations, language commands, object detections, semantic subtask prediction, and low-level actions. Our experiments show that this kind of knowledge transfer is essential for effective generalization, and we demonstrate for the first time that an end-to-end learning-enabled robotic system can perform long-horizon and dexterous manipulation skills, such as cleaning a kitchen or bedroom, in entirely new homes.
Research Tags:
- Computer Science - Robotics
- Machine Learning (cs.LG)
<!—-SPDX-License-Identifier: MIT> <!—-Copyright (c) 2025 qq7r. All rights reserved.>
1. 研究背景与动机
- 研究背景: 当前机器人学习系统(如VLA模型)虽然在实验室环境下表现优异,但在开放世界的泛化能力有限,尤其是在复杂、长视野任务(如家庭清洁)中表现不佳。现有方法主要依赖大规模机器人数据收集,但难以覆盖真实环境的多样性[63,67]。视觉-语言-动作(VLA)模型通过多模态融合提供了一定泛化能力,但在全新场景中的长期任务执行仍面临挑战[8,23]。
- 研究动机: 作者旨在解决机器人跨环境泛化能力不足的核心问题,特别是针对未经训练的家庭场景中的多阶段任务(如厨房清洁)。其动机源于人类可通过多源知识(如语言指令、跨任务经验)快速适应新环境,而现有机器人系统缺乏类似能力。通过异构数据协同训练(如其他机器人数据、语义预测、网络数据),探索模型能否实现类似人类的开放世界泛化[64,92]。
2. 创新贡献
- 异构协同训练框架:提出π0.5模型,整合移动机械臂数据、静态机械臂数据、实验室跨 embodiment 数据、高级语义预测及网络多模态数据(如VQA、目标检测),显著提升泛化能力(97.6%训练数据来自非目标场景)[Fig.1]。
- 分层推理架构:创新性地将高/低层推理统一于同一模型,运行时先预测语义子任务(如“拿起盘子”),再生成底层动作,兼顾长视野规划与细粒度控制[Fig.3]。
- 混合动作表示:结合离散FAST tokenizer(高效训练)与连续flow matching(实时推理),首次实现两种表示联合优化[IV-B]。
- 实证验证:首次展示端到端学习系统在全新家庭环境中完成10-15分钟复杂任务(如整理卧室),成功率超基线模型30%以上[V-A]。
3. 研究方法
模型架构
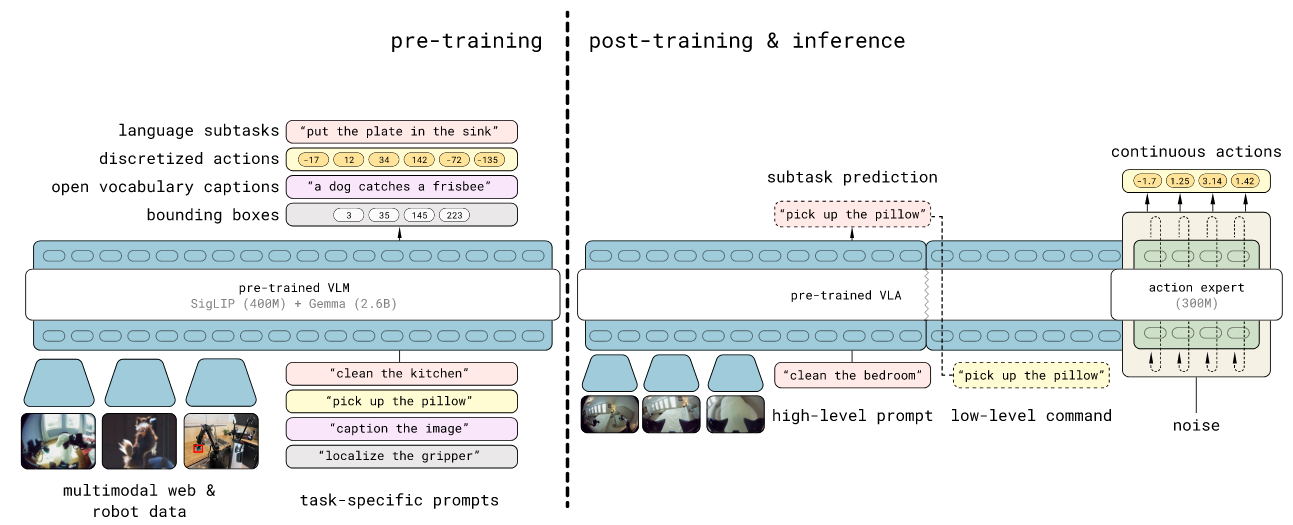
双阶段训练:
- 预训练阶段:统一用离散token处理所有任务(包括文本、物体位置、FAST离散动作),采用标准自回归Transformer。
- 后训练阶段:添加flow matching动作专家模块,专精于连续动作生成,保留文本生成能力。
多模态融合:
- 输入:四摄像头图像(手腕/前后)、语言指令、机器人状态(token化)。
- 输出:子任务文本(如“关闭抽屉”)+动作流向量。关键创新为双向注意力机制(图像/文本)与动作专家隔离(防信息泄露)[Fig.18]。
算法设计
分层推理: $π_θ(a_{t:t+H}, lˆ|o_t, l) = π_θ(a_{t:t+H} |o_t, lˆ) π_θ(lˆ|o_t, l)$ ,子任务预测与动作生成解耦。高层次推理捕捉πθ(lˆ|ot, l),低层次推理捕捉πθ(at:t+H |ot, lˆ),这两个分布由同一模型表示。
- 结合离散与连续动作表征: 模型同时输出自回归离散动作token与Flow matching动作专家的条件;自回归目标使用FAST编码动作token,Flow Matching优化采用Beta分布采样时间步(α=1.5, β=1),侧重低噪声阶段以提升收敛[E]。联合损失函数:$E_{D,τ,ω} [ H( x_{1:M}) , f^l_θ (o_t, l)) + α||ω − a_{t:t+H} − f^a_θ (a^{τ,ω}_{t:t+H} , o_t, l)||^2]$
注意到: 两种action表征方式相互独立,(fast的自回归 action token 与Flow matching的action chunk),信息是单向地从视觉语言模型(VLM)流向动作专家,在Attention层面上直接隔离VLM与动作专家;
预训练:统一的自回归目标,使用5类数据:MM,ME,CE,HL,WD;HL用来训练模型额外预测高层语义子任务分解,WD用来训练模型视觉理解能力(VLM视觉目标)。
- 后训练:添加 flow matching动作专家,使用MM,ME,WD,HL,额外使用VI数据集强化模型预测高层子任务指令。
注意到: pi0.5使用额外的高质量专家数据,用来训练subtask的分解(高层规划)能力,让subtask(VI)与VLM输出的text token对齐。
数据处理
数据来源:
- 机器人数据:400小时移动机械臂(MM)、多环境静态机械臂(ME)、实验室跨平台数据(CE)。
- 非机器人数据:语义子任务标注(HL)、多模态互联网数据(WD)、人类语言指导(VI)[Fig.4]。
预处理: 图像增强(随机裁剪、旋转、色彩抖动),动作归一化至[-1,1](使用1%/99%分位数)[App.C]。
4. 实验设计与结果
实验设置
硬件:双6自由度移动机械臂(4相机+升降 torso),50Hz PD控制[IV-E]。
基准任务:
- 厨房任务(摆餐具、收抽屉)、卧室任务(叠衣服、铺床),每个任务10次试验[App.B]。
对比基线: π0(纯flow matching)、π0-FAST+Flow(混合动作表示)、GPT-4(零 shot子任务生成)[V-D]。
评估指标:
- 任务完成度(按步骤得分,如“餐具入槽”成功得1分)。
- 语言跟随率(选择正确对象概率)。
主结果
跨环境泛化:在3个全新真实家庭中,π0.5平均任务完成度达78%,较π0提高32%[Fig.7]。

数据效率:泛化能力随训练数据中环境数量的增加而提升,同时多数据源的预训练对模型泛化非常关键,仅需104个训练场景即可匹配“见过测试场景”的模型性能(p>0.05)[Fig.8]。语言跟随率随训练数据的环境数量增加和提升,同时语言跟随率与任务成功率同步提高(模型语言跟随率也影响泛化能力)[Fig. 9, 15;附录C]
消融实验
协同训练数据成分分析:
- 移除跨 embodiment数据(ME/CE)导致性能下降40%,证明异构数据必要性[Fig.10]。
- 互联网数据(WD)对OOD物体理解关键(语言跟随率↓15%)[Fig.11]。
推理机制分析:
禁用高层推理(implicit HL)性能仅降8%,显示训练数据隐含子任务推理能力[Fig.13]。
移除预训练的HL、WD数据,后训练的VI数据(小规模关键微调数据)都导致模型性能严重下降,体现高层推理机制的对提升泛化能力重要性。
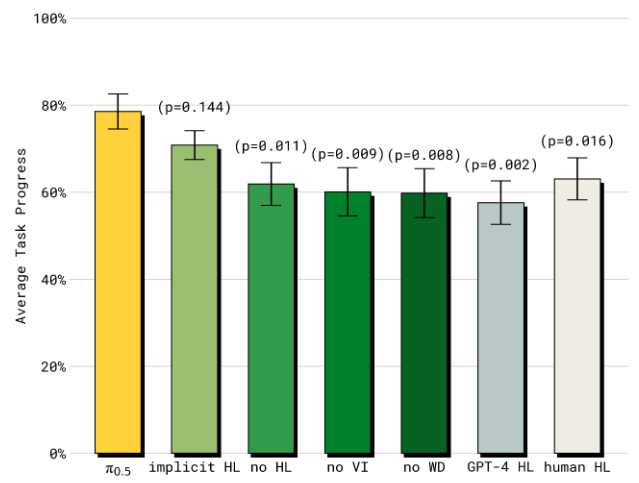
人类子任务标注优于GPT-4(+25%),体现领域适配重要性[V-E]。
5. 相关工作
- 通用机器人策略:对比RT-X[63]、Octo[62]等跨 embodiment 框架,π0.5使用精心设计的数据融合配方,以提升泛化[IV]。
- 使用语言的机器人推理与规划:改进Palme[23]和OpenVLA[42]的纯动作预测范式,引入分层推理,并统一使用一个模型实现。
- 开放世界泛化:突破GR00T[7]等专用系统的限制,不再局限于简单的短时任务,能够实现通用长视野任务[92]。
6. 总结与启示
(1)工作总览
π0.5通过异构协同训练与分层推理架构,解决了机器人在全新家庭环境中执行长视野任务的泛化难题,实验表明其仅需中等规模目标数据即可实现跨场景任务(如清洁厨房)的成功率78%,较基线提升30%以上。
(2)领域启示
- 方法论:验证了多源知识迁移对机器人泛化的关键作用,尤其是非机器人数据(如互联网VQA)的语义辅助。
- 应用:开辟了“小数据+多源预训练”的机器人学习新范式,降低真实数据收集成本。
- 局限性:依赖高质量子任务标注(VI数据仅占11%),未来需探索自动标注或LLM合成。
(3)批判性思考
- 风险:任务复杂度局限于结构化家庭场景,未测试极端动态环境(如人机交互)。
- 开放问题:flow matching的计算成本是否阻碍更大规模训练?(当前需10去噪步骤[IV-B])