GR00T
关于GR00T N1的论文笔记,提出了一个双系统架构的VLA基础模型,用于通用人形机器人。
Comment: Authors are listed alphabetically. Project leads are Linxi “Jim” Fan and Yuke Zhu. For more information, see https://developer.nvidia.com/isaac/gr00t
Meta Data
Title: GR00T N1: an open foundation model for generalist humanoid robots (2025-03-27)
Author: Nvidia; Johan Bjorck; Fernando Castañeda; Nikita Cherniadev; Xingye Da; et al.
ArXiv id: arXiv:2503.14734
Local Link: Nvidia 等 - 2025 - GR00T N1 an open foundation model for generalist humanoid robots.pdf
Abstract:\ General-purpose robots need a versatile body and an intelligent mind. Recent advancements in humanoid robots have shown great promise as a hardware platform for building generalist autonomy in the human world. A robot foundation model, trained on massive and diverse data sources, is essential for enabling the robots to reason about novel situations, robustly handle real-world variability, and rapidly learn new tasks. To this end, we introduce GR00T N1, an open foundation model for humanoid robots. GR00T N1 is a Vision-Language-Action (VLA) model with a dual-system architecture. The vision-language module (System 2) interprets the environment through vision and language instructions. The subsequent diffusion transformer module (System 1) generates fluid motor actions in real time. Both modules are tightly coupled and jointly trained end-to-end. We train GR00T N1 with a heterogeneous mixture of real-robot trajectories, human videos, and synthetically generated datasets. We show that our generalist robot model GR00T N1 outperforms the state-of-the-art imitation learning baselines on standard simulation benchmarks across multiple robot embodiments. Furthermore, we deploy our model on the Fourier GR-1 humanoid robot for language-conditioned bimanual manipulation tasks, achieving strong performance with high data efficiency.
Research Tags:
- Computer Science - Artificial Intelligence
- Computer Science - Machine Learning
- Computer Science - Robotics
<!—-SPDX-License-Identifier: MIT> <!—-Copyright (c) 2025 qq7r. All rights reserved.>
1. 研究背景与动机
- 研究背景:\ 通用人形机器人需要硬件平台(如类人躯体)和智能模型的双重支持。当前机器人学习面临两大挑战:\ (1)缺乏大规模多样化的人形机器人数据(“数据孤岛”问题);\ (2)现有模型对跨任务、跨形态泛化能力不足(Open X-Embodiment Collaboration et al., 2024)[74]。
- 研究动机:\ 作者提出GR00T N1,旨在构建一个融合视觉-语言-动作(VLA)的开源基础模型,通过异构数据源(互联网数据&人类视频+仿真数据+真实机器人数据)训练解决数据稀缺问题,并支持多形态机器人快速适应新任务。
2. 创新贡献
- 双系统架构:结合慢速推理的System 2(视觉-语言模块)与快速响应的System 1(动作生成模块),模拟人类认知机制(Kahneman, 2011)[46]。
- 数据金字塔策略:混合人类视频(18.1M帧)、仿真数据(125.5M帧)和真实机器人数据(26.2M帧),构建异构训练集(表7)[28]。
- 神经轨迹生成技术:通过视频生成模型扩增真实数据10倍(827小时),解决长尾任务覆盖问题(图5)[87]。
- 跨形态支持:单一模型权重适配从机械臂到人形机器人的多种形态(如GR-1、Franka Panda等)。
3. 研究方法
模型架构:
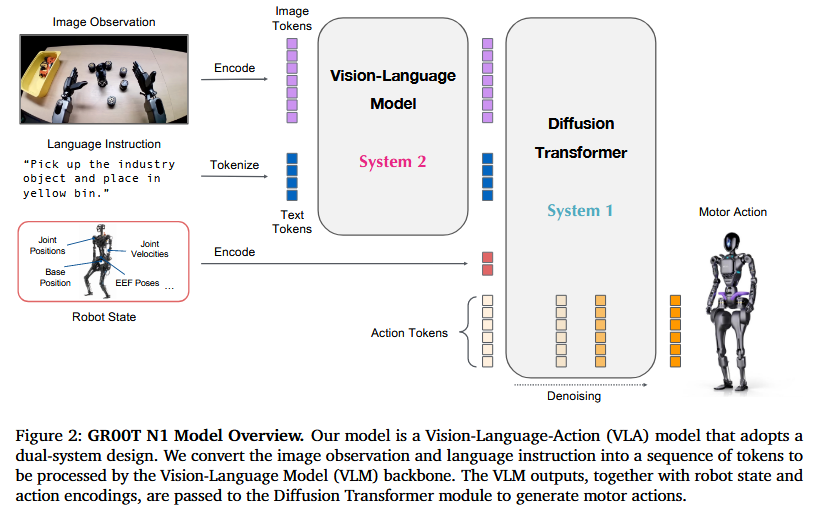
- System 2:基于Eagle-2 VLM(Li et al., 2025)[52],处理图像和语言指令,输出任务语义(10Hz)。
- System 1:扩散Transformer(DiT)[76]通过流匹配(Lipman et al.)[56]生成120Hz动作,跨注意力机制融合System 2输出(图3),支持广泛的机器人实体形态(使用特定实体对应的编码器和解码器),并能通 过数据高效的后训练实现对新任务的快速适应。
算法设计:
- 动作分块处理(H=16),通过4步去噪生成平滑轨迹(式1)[56]。
- 在不同数据源的协同训练中使用潜在动作编码(Ye et al., 2025)[97]和逆动力学模型(IDM)实现无动作视频的伪标注。
数据处理:
- 真实数据:GR-1人形机器人88小时遥操作数据(VIVE追踪器+Xsens手套)。
- 合成数据:利用遥操作数据微调image-to-video模型合成约10x的神经轨迹;DexMimicGen[45]自动生成6500小时仿真轨迹。
- 整合多个数据源,构建了一个结构一致的数据集,其输入包含机器人状态、视觉观测和语言指令,输出为相应动作。
4. 实验设计与结果
实验设置
- 硬件:NVIDIA H100集群(1024 GPU),L40部署。
- 基准数据集:RoboCasa(24任务)、DexMimicGen(9任务)、GR-1(24任务)三大仿真基准+真实场景四类任务(图8)。
- 基准模型:BC-Transformer (Mandlekar et al., 2021)[66], Diffusion Policy(Brohan et al., 2023)[21],作为对比基线。
- 指标:任务成功率(100次试验均值)。
对比实验结果
- 仿真任务:GR00T-N1-2B在GR-1任务上以50%成功率超越Diffusion Policy基线17.3%(表2)[21]。
- 真实任务:仅用10%数据达到Diffusion Policy全量数据性能的90%(表3)[21]。
消融实验
- 神经轨迹:在RoboCasa任务中,LAPA伪标注在低数据量(30样本/任务)时优于IDM,但随数据量增加差距缩小(图9)。
- 双系统协同:移除System 2导致语言指令跟随错误率上升38%(未显式报告,可从图11推测)。
5. 相关工作
领域梳理:
- VLA模型:RT-2(Brohan et al., 2023)[13]与Octo(Octo Model Team, 2024)[73]聚焦单一形态,GR00T N1首次支持人形机器人。
- 数据生成:VideoGPT(Brooks et al., 2024)[17]生成虚拟轨迹,但未与真实数据联合训练。
对比分析:相比BC-Transformer[65],GR00T N1通过扩散策略提升动作连续性(图12)。
6. 总结与启示
(1)工作总览
GR00T N1通过双系统VLA模型和异构数据金字塔,解决了人形机器人跨任务泛化与数据稀缺问题,在仿真和真实任务中分别取得50%和76.8%的平均成功率。
(2)领域启示
- 方法论:证明了扩散模型+VLMs在具身智能中的协同有效性。
- 数据策略:神经轨迹生成可低成本扩展机器人数据(10倍增益)。
- 开源意义:首个支持多形态的开源人形机器人基础模型(GitHub/HuggingFace)。
(3)批判性思考
- 长时程局限:当前模型仅针对桌面级短时程任务,未测试locomotion等复杂场景。
- 物理一致性:神经轨迹的物理合理性依赖生成模型质量(如液体模拟,图13)。