GR-2
这篇文章为GR-2技术报告,提出了一种基于视频-语言-动作模型的基座模型GR-2,该模型在互联网视频上进行自回归预训练(预测未来帧),再通过后训练预测视频token与动作token,能够泛化到各种机器人任务和环境。
Comment: Tech Report. Authors are listed in alphabetical order.
Project page: https://gr2-manipulation.github.io
Meta Data
Title: GR-2: a generative video-language-action model with web-scale knowledge for robot manipulation (2024-10-08)
Author: Chi-Lam Cheang; Guangzeng Chen; Ya Jing; Tao Kong; Hang Li; et al. (ByteDance Research)
ArXiv id: arXiv:2410.06158
Abstract:\ We present GR-2, a state-of-the-art generalist robot agent for versatile and generalizable robot manipulation. GR-2 is first pre-trained on a vast number of Internet videos to capture the dynamics of the world. This large-scale pre-training, involving 38 million video clips and over 50 billion tokens, equips GR-2 with the ability to generalize across a wide range of robotic tasks and environments during subsequent policy learning. Following this, GR-2 is fine-tuned for both video generation and action prediction using robot trajectories. It exhibits impressive multi-task learning capabilities, achieving an average success rate of 97.7% across more than 100 tasks. Moreover, GR-2 demonstrates exceptional generalization to new, previously unseen scenarios, including novel backgrounds, environments, objects, and tasks. Notably, GR-2 scales effectively with model size, underscoring its potential for continued growth and application. Project page: \url{https://gr2-manipulation.github.io}.
Research Tags:
- Computer Science - Computer Vision and Pattern Recognition
- Computer Science - Machine Learning
- Computer Science - Robotics
<!—-SPDX-License-Identifier: MIT> <!—-Copyright (c) 2025 qq7r. All rights reserved.>
1. 研究背景与动机
- 研究背景: 通用机器人操纵长期依赖大规模任务专属数据,但现实数据收集效率低且成本高。现有基于互联网预训练的基础模型(如CLIP、GPT)在语言和视觉任务中表现优异,但机器人领域缺乏类似范式 [5][15]。
- 研究动机: 作者旨在构建一个可通过视频生成预训练获取世界动态先验的通用机器人代理,解决小样本多任务泛化和跨场景适应两大挑战,降低机器人技能学习成本 [5]。
2. 创新贡献
- 超大规模预训练:首次在机器人领域引入3800万视频片段(500亿token)的生成式预训练,较前作GR-1数据量提升47倍 [5]。
- 无损知识迁移架构:设计统一架构实现视频生成预训练到动作预测的无缝转换,支持多视角输入和轨迹级动作输出 。
- 工业级控制部署:提出结合轨迹优化与实时运动跟踪的全身控制算法(WBC),执行频率达200Hz [20]。
- 数据增强策略:利用扩散模型和视频生成模型实现背景替换与物体插入,提升后训练模型泛化性 [22][25]。
3. 研究方法
模型架构: GPT风格多模态Transformer,输入包括语言指令(CLIP文本编码器)、视频帧(VQGAN离散化)、机器人状态(线性编码),输出未来帧和动作轨迹(cVAE生成) [6][7][17]。
算法流程: 两阶段训练:
- ① 互联网视频预训练,自回归预测优化目标(文本+帧→预测未来帧);
- ② 机器人数据微调(多视角视频+状态→联合预测动作和帧) [2]。
数据处理:
- 预训练数据:整合Howto100M(36M)、Ego4D(1.2M)等38M视频,通过人工过滤和重标注优化[8][9][13][14]。
- 机器人数据:自采集人类演示,包含105项任务40k轨迹(平均400轨迹/任务),采用扩散模型“插入新物体”进行数据增强,从而增强物体多样性[22][23],再利用SAM[24]以及video generation model[25]增强视频的同时,保持机器人运动 。
4. 实验设计与结果
实验设置
硬件:Kinova Gen3机械臂+Robotiq 2F-85夹爪,双相机系统 。
基准任务:
- 多任务学习:105项桌面任务(8类技能),5种测试场景(Simple/Distractor/Unseen等) [21]。
- 分拣任务:122物体(67未见物体)的4种分拣场景 。
- CALVIN[21]仿真基准:34种长时操纵任务
对比方法:GR-1、RT-1、MT-ACT、HULC、RoboFlamigo等[5][15][26][27][28]。
评估指标:成功率(Multi-Task)、平均任务链长度(CALVIN) [21]。
对比实验结果
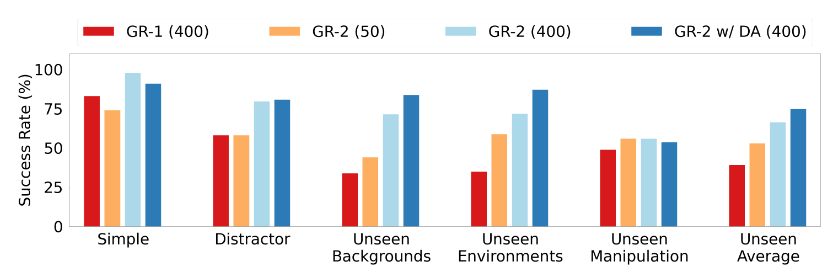
多任务学习:平均成功率97.7%(Simple),在Unseen Environments达87.0%(较GR-1[5]提升24.3%)[Fig. 6]。
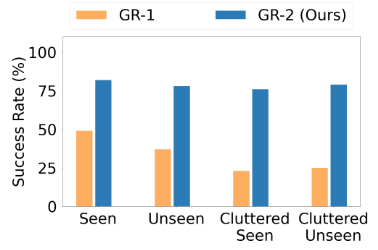
分拣任务:未见物体成功率79.0%(GR-1仅33.3%)[Fig. 9] 。
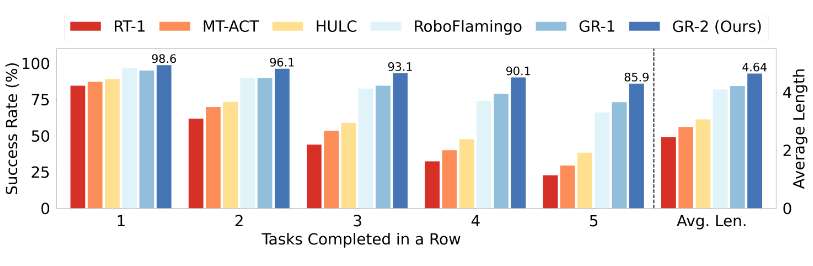
CALVIN基准[21]:单任务成功率98.6%,5任务链成功率85.9%(SOTA,较GR-1提升12.8%) [Fig. 10]。
消融实验
- 数据规模:预训练数据从0.8M→38M,Unseen Environments成功率翻倍 [5]。
- 模型规模:参数从30M→719M,验证损失线性下降,成功率提升12.4% 。
- 轨迹生成:cVAE生成轨迹较单步动作预测提升7.2%成功率 [17][19]???。
5. 相关工作
- 通用机器人学习:对比RT-2(语言驱动)和Octo(多任务策略),GR-2强调视频生成对动作预测的引导作用[15][29][36]。
- 预训练范式:区别于RPT(自监督预训练)和VIPER(视频预测奖励),GR-2通过联合生成视频-动作实现知识迁移[5][55][65]。
- 工业分拣:较传统模型方法,GR-2首次实现透明/变形物体的零样本分拣 [37]。
6. 总结与启示
(1)工作总览
GR-2通过视频生成预训练和机器人数据微调,构建了一个能执行105+任务、分拣122+物体的通用代理,在CALVIN等基准上刷新SOTA,核心创新在于生成式预训练架构和多模态动作生成。
(2)领域启示
- 方法论:验证了视频生成作为世界模型对机器人动作预测的有效性 [67]。
- 应用:为工业分拣提供了零样本适配方案(如透明物体处理) [37]。
- 资源效率:50轨迹/任务即可达73.9%成功率,降低数据依赖 。
(3)批判性思考
- 物理约束:依赖WBC算法处理碰撞,纯视觉策略在密集物体场景可能失效 [20]。
- 动态交互:未验证高速运动物体(如传送带分拣)的适应性 。